22 aprile 2026 — QTNova
Quando entriamo in una conversazione commerciale con un cliente che vuole "un progetto di intelligenza artificiale", raramente quest'ultimo sa in cosa consiste e quali aspettative avere. "In fondo è un progetto software come gli altri, no?".
La risposta onesta è: sì e no. Il ciclo di vita in senso astratto è lo stesso — si parte da un problema di business, si definiscono requisiti, si scrive codice, si testa, si rilascia, si manutiene. Ma ciò che accade all'interno di quel ciclo, e soprattutto come si misura se il sistema funziona, cambia in modo sostanziale quando al centro c'è un modello di linguaggio.
In questo articolo raccontiamo due progetti reali che abbiamo portato in produzione nel 2025-2026, con livelli di complessità molto diversi tra loro, e proviamo a mostrare concretamente dove sta la differenza.
Per riservatezza verso i clienti useremo le etichette Cliente A (azienda manifatturiera lombarda) e Cliente B (produttore italiano di componentistica per ascensori). Tutti i riferimenti tecnici sono autentici.
Introduzione: software deterministico vs software probabilistico
Lo sviluppo software tradizionale si regge su una proprietà fondamentale: è deterministico. Dato un input, e dato lo stato del sistema, l'output è prevedibile. Una funzione che somma due numeri, a parità di argomenti, restituirà sempre lo stesso risultato. Questa proprietà è ciò che ci permette di scrivere una specifica, di codificare dei test, e di affermare con ragionevole sicurezza che "il sistema funziona" quando tutti i test passano.
Su questa base si fonda una pratica come il Test Driven Development, formalizzata da Kent Beck: scrivere prima un test che fallisce (red), poi il codice minimo per farlo passare (green), poi rifattorizzare (refactor). Il ciclo funziona perché ogni asserzione è vera o falsa in modo inequivocabile.
Attenzione però: già nel software classico esistono limiti teorici insuperabili a ciò che un test può garantire. Due risultati storici ce lo ricordano:
- Il problema della terminazione di Turing (1936) dimostra che non può esistere un algoritmo generale capace di stabilire, per un programma arbitrario, se quel programma terminerà o meno;
- Il teorema di Rice (1951) generalizza il risultato: qualsiasi proprietà semantica non banale di un programma è indecidibile.
In pratica: non esiste e non può esistere un "super-test" che verifichi automaticamente se un programma fa ciò che ci aspettiamo. I test coprono statement specifici — asserzioni puntuali su comportamenti puntuali — e dalla densità e qualità di queste asserzioni dipende la nostra confidenza. Ma restano un'approssimazione. Il TDD funziona perché accetta questo limite e costruisce, iterativamente, un reticolo di asserzioni sufficientemente fitto da rendere i regressi immediatamente visibili.
Ora passiamo ai sistemi basati su LLM. Qui la musica cambia, e per almeno tre ragioni:
1. L'output non è deterministico nemmeno a parità di input. Anche azzerando parametri come la "creatività" del modello (in gergo "temperatura") e seed fissati, la stessa domanda (prompt) può produrre risposte differenti da una chiamata all'altra. Il motivo è più profondo di quanto si pensi: è legato al modo in cui i kernel GPU gestiscono il batching durante l'inferenza, e non si risolve con qualche flag. Per chi vuole approfondire, questo articolo di Thinking Machines Lab entra nel dettaglio tecnico, mentre un post recente di Sara Zan lo spiega in modo accessibile.
2. L'output è spesso in linguaggio naturale. Non un booleano, non un intero, non un JSON: una frase, un paragrafo, una spiegazione. Come si fa a dire se una risposta in italiano a una domanda tecnica è "corretta"? Esistono infinite formulazioni equivalenti, e il confronto stringa-contro-stringa non ha alcun senso.
3. Il comportamento del sistema dipende da variabili che nel software classico non esistono. Modello scelto, versione del modello, prompt di sistema, temperatura, tool collegati, contesto recuperato da un vector store, ordine in cui vengono presentate le informazioni. Ogni scelta influisce sulla qualità e ogni modifica può migliorare alcune risposte e peggiorarne altre.
Per questo l'industria ha smesso di parlare di testing e ha iniziato a parlare di evaluation. Come dice la documentazione di OpenAI: i metodi tradizionali di test sono insufficienti per sistemi AI, servono gli eval. Anthropic ha pubblicato un intero lavoro sulle sfide della valutazione dei sistemi AI che mostra come anche piccole modifiche al formatting di un prompt possano far variare di diversi punti percentuali le metriche di un modello. Chi ha lavorato su sistemi LLM in produzione — vedi la raccolta collettiva Applied LLMs di Yan, Bischof, Husain e altri — concorda su una cosa: la qualità di un sistema AI in produzione si regge sulla qualità del suo sistema di eval, non sulla qualità del modello.
Esiste persino un nome per questo approccio: Evaluation-Driven Development, per analogia con il TDD. Lo trovate formalizzato nel blog di MLflow, lo strumento che abbiamo utilizzato per il secondo progetto.
Con questa cornice in testa, passiamo ai due casi concreti.
Ok, ma nella pratica?
Oggi, 22 aprile 2026, vogliamo raccontarvi due progetti di intelligenza artificiale con due gradi di difficoltà molto differenti.
Il primo è attualmente in produzione presso il Cliente A, un'azienda manifatturiera lombarda, e si occupa di trasformare email di ordini e richieste di offerta — che arrivano in formati eterogenei e non strutturati — in record puliti e strutturati nel gestionale aziendale.
Il secondo è in pre-produzione presso il Cliente B, un produttore italiano di componentistica per ascensori, e consiste in un assistente virtuale diagnostico che supporta i tecnici manutentori in campo nell'interpretazione di schemi elettrici e manuali tecnici.
Perché abbiamo scelto proprio questi due progetti, se in apparenza si collocano entrambi nello stesso "ciclo di vita AI"? Perché illustrano perfettamente due livelli di difficoltà molto diversi.
Il progetto del Cliente A ha un cuore tecnico relativamente contenuto dal punto di vista AI: si tratta di estrarre informazioni da un formato non strutturato (o semi-strutturato) a un formato strutturato. L'output atteso è un JSON con campi ben definiti — un codice prodotto, una quantità, un prezzo — che alimenta un flusso software tradizionale. La valutazione è binaria: il valore estratto è uguale a quello atteso, oppure no.
Il progetto del Cliente B è invece di una complessità molto più significativa. C'è una componente di RAG (Retrieval Augmented Generation, introdotto nel paper di Lewis et al. nel 2020) con embedding e vector store per i manuali tecnici. C'è una componente di ottimizzazione del contesto, perché il corpus documentale è grande e serve presentare al modello solo ciò che è effettivamente pertinente alla domanda specifica. C'è una componente di prompt engineering con regole domain-specific sull'interpretazione degli schemi elettrici. C'è una componente di preprocessing delle immagini basata su computer vision. C'è una componente di tool calling che permette al modello di usare strumenti deterministici (come l'esecuzione di codice) per migliorare la qualità dell'output. E soprattutto c'è una componente di output non strutturato: la risposta è una spiegazione in linguaggio naturale a un tecnico in campo, e va valutata come tale.
Vedremo come nel primo caso la valutazione sia quasi "old style" — si misura un tasso di accuratezza puntuale su un dataset e si itera — mentre nel secondo caso la valutazione diventi essa stessa un'attività ingegneristica, con scorer multipli, confronti sistematici tra configurazioni, e soprattutto dati quantitativi che mostrano l'impatto di ogni singola modifica a prompt, preprocessing, modello o strumenti.
Cliente A — L'estrazione strutturata dal caos delle email
Il problema
Il Cliente A è un gruppo industriale che gestisce anagrafica, catalogo e ordini su un ERP legacy basato su SQL Server. L'ERP funziona, è profondamente integrato con magazzino, spedizioni e fatturazione, e sostituirlo nel breve termine non è un'opzione. Il front-end commerciale, però, è inefficiente: gli ordini dai clienti arrivano via email, con allegati PDF o Excel, o direttamente nel corpo del messaggio come testo libero. Ogni cliente usa un proprio template. Alcuni elencano i prodotti in una tabella, altri in un elenco puntato, altri ancora in una frase discorsiva.
Gli operatori del Cliente A dedicavano una parte significativa della loro giornata a leggere queste email e trascrivere manualmente gli ordini nel gestionale. Un'attività lenta, ripetitiva, ad alto tasso di errore — e soprattutto difficile da scalare in fasi di picco.
La risoluzione
Abbiamo progettato un sistema ibrido a due componenti:
- Un front-end moderno basato su Odoo, dove atterrano le email cliente. Un assistente AI legge automaticamente il contenuto dell'email e degli allegati ed estrae un JSON strutturato con testata (cliente, indirizzo di consegna, data, riferimento d'ordine) e righe (codice articolo, quantità, prezzo unitario, eventuali certificazioni alimentari, data di consegna). Un operatore, che chiamiamo Requests Operator, rivede i casi ambigui — cliente non identificato, SKU multi-match, indirizzo non presente a catalogo — e conferma l'ordine.
- Un container Python di sincronizzazione che ogni tot tempo legge incrementalmente dall'ERP legacy e aggiorna Odoo: articoli, partner, indirizzi, condizioni di pagamento, storico ordini. Quando l'operatore conferma l'ordine lato Odoo, il sistema invia un feedback all'ERP tramite una chiamata REST che crea la richiesta di offerta nel sistema originale. Il legacy resta master per fulfillment e fatturazione; Odoo diventa master per la presa in carico dell'ordine.
Il valore misurabile è netto: riduzione del tempo di lavorazione per ordine, abbattimento degli errori di trascrizione, visibilità real-time ai commerciali e alle operations senza obbligarli a lavorare direttamente sul legacy (e tutti i vantaggi che porta con sé un software come Odoo, storico delle modifiche, note su offerte e ordini e la possibilità di conversare tra gli utenti del software).
Il processo
Come si sviluppa un progetto come questo? Ripercorriamolo nelle sue fasi, sottolineando dove la componente AI introduce considerazioni nuove.
Fase 1 — Raccolta del campione. Prima di qualsiasi scelta tecnica, abbiamo raccolto insieme al cliente un campione diversificato di documenti reali: PDF, Excel, email testuali, ordini con layout tabellare, ordini con righe "in prosa", casi con certificazioni alimentari, casi con indirizzi di consegna multipli. Senza un campione rappresentativo, qualunque benchmark successivo sarebbe stato falsato.
Fase 2 — Primi test di estrazione in linguaggio naturale. In questa fase non ci interessa ancora la forma dell'output: vogliamo capire se il modello scelto — nel nostro caso GPT-5.2 tramite l'ecosistema di adapter che abbiamo sviluppato internamente — ha la capacità di comprendere i documenti. Gli passiamo un PDF e gli chiediamo, in linguaggio libero: "cosa ordina questo cliente?". Se la risposta dimostra "comprensione", siamo a posto; se il modello si inventa prodotti o ignora allegati, sappiamo che il problema è alla radice e che nessuna ottimizzazione downstream lo risolverà.
Questo step è anche il momento in cui confermiamo la fattibilità commerciale del progetto. Se l'AI non riesce nemmeno a leggere i documenti del cliente, non ha senso andare avanti.
Fase 3 — Definizione dell'output strutturato. Superata la fase di feasibility, passiamo a rendere l'AI capace di formattare l'output in uno schema rigoroso: testata con customerVatCode, orderReference, deliveryAddress, deliveryDate, e righe con skuReference, description, quantity, unitPrice, discount, revision, più un set di booleani per le certificazioni alimentari (Food Grade, MOCA, Material Detectable, FDA). Questo schema è il contratto tra la parte probabilistica del sistema (l'AI) e la parte deterministica (il nostro software), che prende l'output, incrocia i dati con catalogo e storico, applica flussi di business specifici — riconoscimento del cliente dal dominio email, matching del codice cliente sulle varianti del prodotto — e alla fine scrive nel gestionale.
Fase 4 — Valutazione e iterazione. Qui arriva il pezzo interessante, ma anche quello relativamente più semplice di questo progetto. Perché per il Cliente A l'output non può essere ambiguo. Se nel documento originale il prezzo è scritto 15.34 oppure 15,340 o ancora 15,34 € (nota punti e virgola utilizzati in maniera differente), ci aspettiamo che il modello estragga sempre 15.34. Stessa cosa per quantità, codici, date: c'è una risposta oggettivamente giusta e il modello deve produrla.
Costruiamo quindi un dataset di ground truth etichettato a mano sui documenti raccolti in fase 1, e iteriamo su prompt e parametri del modello misurando il tasso di match esatto campo per campo. Con un paio di iterazioni sul prompt siamo arrivati al 100% di accuratezza sul nostro dataset.
Un esempio concreto di iterazione: alcuni clienti specifici inviano ordini in cui lo stesso prodotto compare con codici duplicati o varianti (un codice interno del cliente più un codice standard). Al primo giro il modello sceglieva in modo casuale. Solo chi conosce il dominio e ha esperienza con quel cliente sa che, in quel caso, il codice rilevante è uno specifico dei due. Una regola nel prompt — "per il cliente X, quando trovi entrambi i codici, scegli il secondo" — ha risolto il problema.
Fase 5 — Staging e go-live. Una volta raggiunte le soglie di accuratezza accettabili, si unisce il software al modello in un ambiente di staging identico alla produzione, si eseguono gli UAT (User Acceptance Test) con gli operatori reali, e si rilascia. Da quel momento in poi il sistema è monitorato in produzione e, quando emergono casi nuovi che mettono in difficoltà il modello, si aggiungono al dataset di valutazione e si itera.
Come si vede, per un progetto di questo tipo il paradigma resta molto vicino a quello classico: c'è una specifica (lo schema JSON), c'è un dataset di test (il campione etichettato), c'è una metrica binaria (match / no match). L'AI è "solo" la componente che produce l'output; tutto il resto è software deterministico che possiamo testare come sempre.
Il progetto del Cliente B ci costringe a uscire da questo schema.
Cliente B — L'assistente diagnostico per tecnici manutentori
Il problema
Il Cliente B produce componenti e quadri elettrici per ascensori. Ogni impianto installato viene consegnato con:
- uno schema elettrico (un PDF di varie pagine) specifico di quel modello;
- una serie di manuali tecnici dei componenti montati (inverter, relè, sensori, schede di controllo) di marche diverse — Mitsubishi, FRENIC, EURO, e molti altri.
Quando un ascensore ha un guasto, interviene un manutentore in campo — un tecnico dipendente dell'azienda installatrice, che è cliente del Cliente B. Questo manutentore deve:
- Capire quale sia il componente in anomalia;
- Interpretare lo schema elettrico per risalire ai collegamenti;
- Consultare i manuali tecnici dei componenti coinvolti;
- Diagnosticare la causa e procedere alla riparazione.
Ogni passaggio richiede tempo, esperienza, e accesso a documentazione che spesso è fisicamente lontana o non aggiornata. Nei casi complessi il manutentore chiama un ingegnere senior del Cliente B, reperibile in orario lavorativo. Ogni intervento produce know-how — la diagnosi, la soluzione, le note — ma questo know-how non viene capitalizzato: resta nella testa del singolo ingegnere o al massimo in una mail archiviata e dato il numero di installazioni sul territorio, il tempo speso dagli ingegneri ha un costo impattante per il cliente B.
La risoluzione
Abbiamo costruito una piattaforma, sempre basata su Odoo, articolata su tre livelli.
Livello 1 — Knowledge base AI-powered. I manuali tecnici dei componenti sono storicamente archiviati dal Cliente B su un file server interno, alimentato giorno dopo giorno dal personale tecnico. In QTNova siamo convinti che un buon progetto AI debba ottimizzare i flussi esistenti, non stravolgerli: abbiamo quindi fatto in modo che il sistema attingesse direttamente da quella stessa fonte di dati, senza chiedere al cliente di cambiare le proprie abitudini operative. I manuali attraversano una pipeline che estrae il testo (con fallback a OCR quando necessario), chiede al modello di estrarre metadata strutturati (nome del componente, produttore, alias), crea il record anagrafico del componente e indicizza il documento in un vector store di Google.
Gli schemi elettrici, invece, attraversano una pipeline di preprocessing basata su computer vision (OpenCV). Qui c'è un dettaglio non scontato: gli schemi originali sono in bianco e nero, come tipicamente avviene nella documentazione tecnica industriale. Per aiutare il modello a interpretarli correttamente, il nostro preprocessor applica una colorazione algoritmica ai fili e alle giunzioni, in modo che ogni connessione risulti annotata in modo visivamente e testualmente inequivocabile. È un pezzo su cui abbiamo investito molto: senza di esso, il modello si confonde costantemente nell'interpretare gli schemi.
Livello 2 — Chatbot diagnostico. Il manutentore accede via livechat a un'interfaccia dedicata. Il chatbot lo guida attraverso alcuni step: accettazione della disclaimer, identificazione dell'impianto (tramite numero PF, l'identificativo che il Cliente B assegna a ogni quadro consegnato, oppure tramite numero di schema), formulazione della domanda. A quel punto entra in gioco l'assistente Gemini 3.1 Pro — al momento dell'avvio del progetto era il modello che, nei nostri test preliminari, performava meglio su questo specifico task, in particolare nella comprensione multimodale di documenti tecnici complessi come gli schemi elettrici. Il modello riceve in contesto lo schema elettrico dell'impianto specifico, ha accesso tramite tool ai manuali dei componenti pertinenti (filtrati per componente, grazie alla mappatura schema → componenti che costruiamo in fase di ingest), e risponde al tecnico.
Livello 3 — Escalation a ticket umano. Quando l'AI non basta — o perché il manutentore esplicitamente lo richiede, o perché il sistema rileva che la conversazione non converge — il chatbot apre automaticamente un ticket helpdesk, precompilato con il transcript della chat, il PF, lo schema, lo stato di garanzia (calcolato sulla data del DDT originale + 12 mesi) e il progetto di assistenza corretto. Un ingegnere del Cliente B lavora il ticket, compila la risoluzione e registra il foglio ore. Alla chiusura del ticket, la risoluzione finale viene indicizzata nel vector store: le conversazioni future potranno recuperare anche le soluzioni storiche pertinenti. Il know-how accumula valore nel tempo.
A questo si aggiungono tracciamento garanzia, gestione progetti di assistenza suddivisi tra "Assistenza" e "Garanzia" e tra anno corrente e anni passati, scadenze automatiche degli accessi AI per i manutentori dei clienti che smettono di ordinare, blocco degli schemi proprietari per utenti non autorizzati. Una piattaforma completa, insomma — non solo una chat.
Il processo
Qui il racconto si fa interessante. Perché se per il Cliente A l'AI era "una feature", per il Cliente B l'AI è il cuore del prodotto, e questo cambia radicalmente il modo in cui si sviluppa e si valuta.
Complessità deterministiche "a corollario". Prima ancora di occuparsi della qualità delle risposte, abbiamo dovuto gestire un'intera serie di problemi classici che un'applicazione conversazionale basata su LLM porta con sé. Mantenere una conversazione consistente se il tecnico perde la connessione mentre il modello sta ancora generando la risposta. Gestire i picchi di domanda lato provider, quando i nuovi modelli vengono rilasciati e iniziano a rifiutare richieste per saturazione: abbiamo implementato exponential backoff con retry e fallback. Limitare il numero massimo di risposte AI per conversazione per evitare derive e costi incontrollati. Rate limiting sugli endpoint. Tutti problemi "deterministici" che si affrontano con testing classico, ma che non esistevano nel progetto del Cliente A.
La vera sfida: come valutiamo le risposte? Il cuore del progetto è una conversazione in linguaggio naturale tra un manutentore e un modello. Non c'è un campo unitPrice da confrontare. La risposta del modello può essere più o meno corretta, più o meno completa, più o meno ancorata alle fonti giuste. Una domanda tipica che un manutentore può fare è: "a che cosa è collegato il morsetto X dello schema Y?". Una domanda apparentemente semplice che porta con sé ambiguità notevoli:
- La risposta deve includere solo i collegamenti diretti al morsetto X, o anche quelli indiretti (cioè i percorsi che attraversano ponti, giunzioni, e altri morsetti)?
- Deve citare le pagine del PDF da cui ha tratto l'informazione? In quale formato?
- Deve usare la nomenclatura presente nello schema o i termini generici dei manuali?
- Se il modello ha a disposizione sia lo schema (nel contesto della conversazione) sia i manuali dei componenti (nel vector store), quale delle due fonti deve privilegiare per questa domanda specifica?
Questo tipo di ambiguità non si risolve con un test unitario. Si risolve definendo criteri di valutazione espliciti e misurabili, costruendo un dataset di domande-risposte attese validato insieme agli esperti di dominio (ingegneri del Cliente B), e misurando sistematicamente l'impatto di ogni modifica al sistema su quei criteri.
Lo strumento: MLflow e l'evaluation matrix. Per questo progetto abbiamo costruito un framework di valutazione basato su MLflow che, per ogni configurazione del sistema, esegue il set completo di conversazioni di test e calcola una batteria di metriche automatiche. Le configurazioni variano lungo più assi:
- Modello (GPT-5.2, GPT-5.4, Gemini 3.1 Pro — con provider OpenAI e Google indipendenti);
- Prompt di sistema (diverse varianti con differenti livelli di dettaglio sulle regole di interpretazione degli schemi);
- Code execution attivato / disattivato;
- Preprocessing degli schemi (nessuno, wire detection, junction detection);
- Tool esterni attivi o no;
- Temperatura del modello.
Per ogni turno di ogni conversazione vengono calcolati più scorer:
- Correctness (giudice LLM, basato su LLM-as-a-Judge): la risposta è fattualmente corretta rispetto alla risposta attesa? Restituisce Pass/Fail.
- Fact recall (giudice LLM custom): quale frazione di "fatti attesi" — una lista di fatti atomici che una risposta corretta dovrebbe contenere — è effettivamente presente nella risposta? Restituisce un valore tra 0 e 1 (Numero di fatti individuati / Numero di fatti totali).
- Completeness: la risposta elenca tutti i collegamenti pertinenti, include riferimenti di pagina, distingue collegamenti diretti da indiretti?
- Plain text format: deterministico, verifica che la risposta non contenga markdown (richiesta esplicita del Cliente B per compatibilità con la chat del manutentore).
- Response length e turn duration: metriche operative.
Il dataset: 14 conversazioni scelte apposta perché difficili. Un aspetto fondamentale da sottolineare per contestualizzare i numeri che stiamo per mostrare: il dataset di valutazione non è rappresentativo delle domande medie che un manutentore può fare. È un dataset costruito insieme agli ingegneri del Cliente B selezionando casi su cui i primi test avevano mostrato che il modello baseline, senza aiuti, sbagliava quasi sistematicamente. Sono 14 conversazioni multi-turno — più di 50 singoli turni — che abbiamo scelto proprio perché volevamo misurare il miglioramento su ciò che era difficile, non su ciò che già funzionava.
Questo è un principio importante: per costruire un sistema AI solido bisogna valutarlo dove è fragile, non dove è banale. E bisogna farlo con un dataset etichettato da domain expert — un lavoro che richiede giorni di sessioni congiunte con i tecnici del cliente.
Le iterazioni e i numeri. Abbiamo eseguito diverse iterazioni sul sistema, ognuna delle quali lasciava le altre variabili costanti e cambiava solo il pezzo che volevamo misurare. Ne riportiamo le quattro più significative.
Iterazione v1 — Baseline con GPT-5.2. È la configurazione di partenza, senza preprocessing sullo schema, con prompt minimale, senza code execution. Il suo scopo è farci da fondo scala.
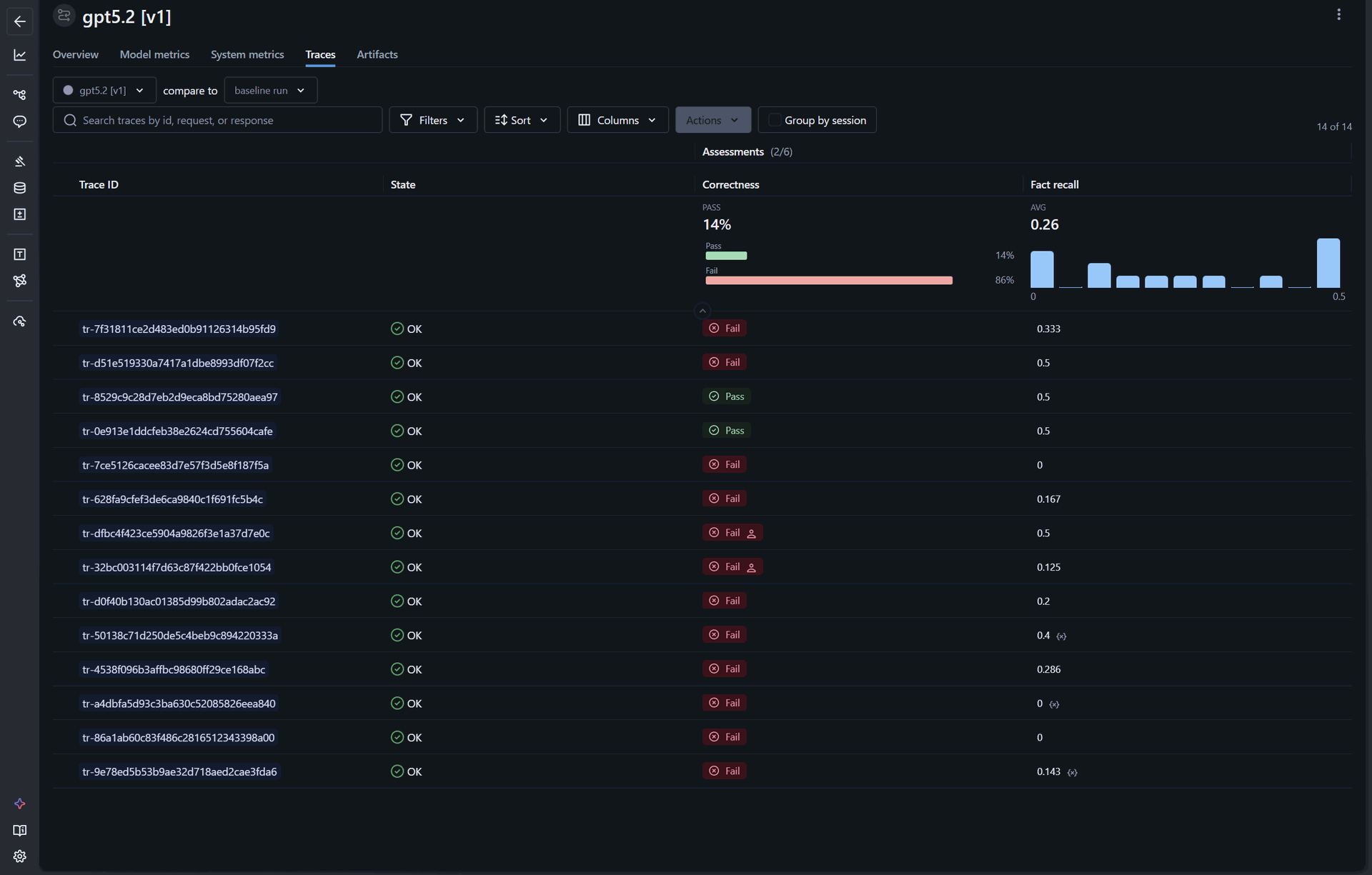
- Correctness: 14% (Pass su Fail)
- Fact recall medio: 0.26
Sul dataset di test "difficile" che avevamo selezionato, il modello senza aiuti passa una conversazione su sette e recupera circa un quarto dei fatti attesi. È un punto di partenza bassissimo, atteso, che serve per avere una base di confronto onesta.
Iterazione v2 — Cambio modello a Gemini 3.1 Pro. Manteniamo tutto identico, cambiamo solo il modello sottostante. Motivazione: Gemini 3.1 Pro ha un thinking mode profondo e una gestione nativa di file multimodali (PDF degli schemi passati come attachment) che ci aspettavamo potesse migliorare la comprensione visuale degli schemi elettrici.
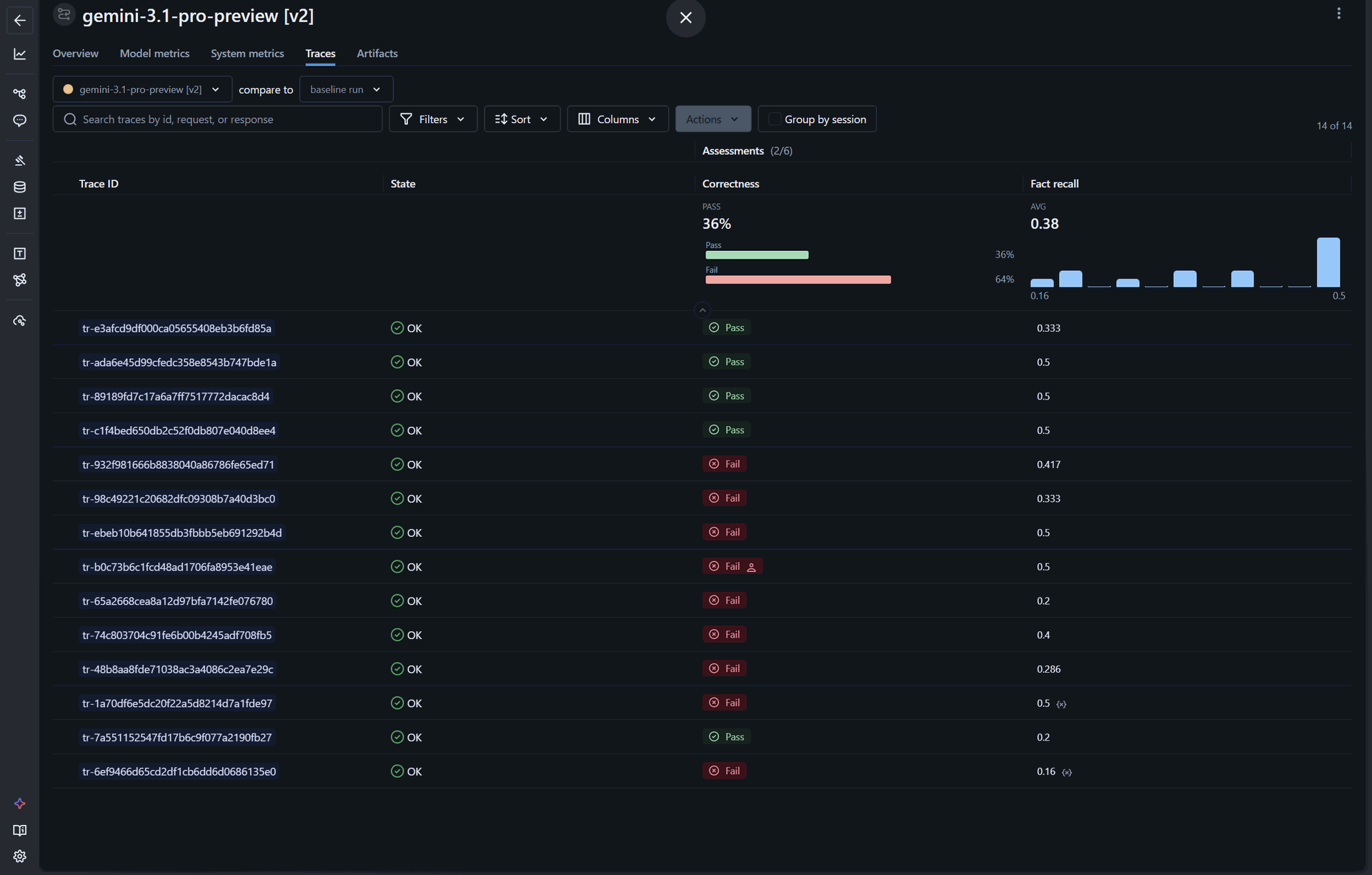
- Correctness: 36% (+22 punti)
- Fact recall medio: 0.38 (+0.12)
Il solo cambio di modello produce un miglioramento sostanziale. Interessante notare che il fact recall cresce meno della correctness: il modello dà risposte più spesso "corrette nel complesso" ma non necessariamente più complete nei dettagli.
Iterazione v3 — Preprocessing degli schemi con wire detection. Qui interviene la parte di computer vision custom che abbiamo costruito. Prima di passare lo schema PDF al modello, un preprocessor rileva i fili colorati e le giunzioni e produce una versione annotata dello schema, dove ogni connessione è esplicitata in modo visivamente e testualmente inequivocabile. Aggiungiamo anche raffinamenti al prompt di sistema con regole specifiche sull'interpretazione del "Foglio 001" (la legenda degli schemi del Cliente B) come source of truth.
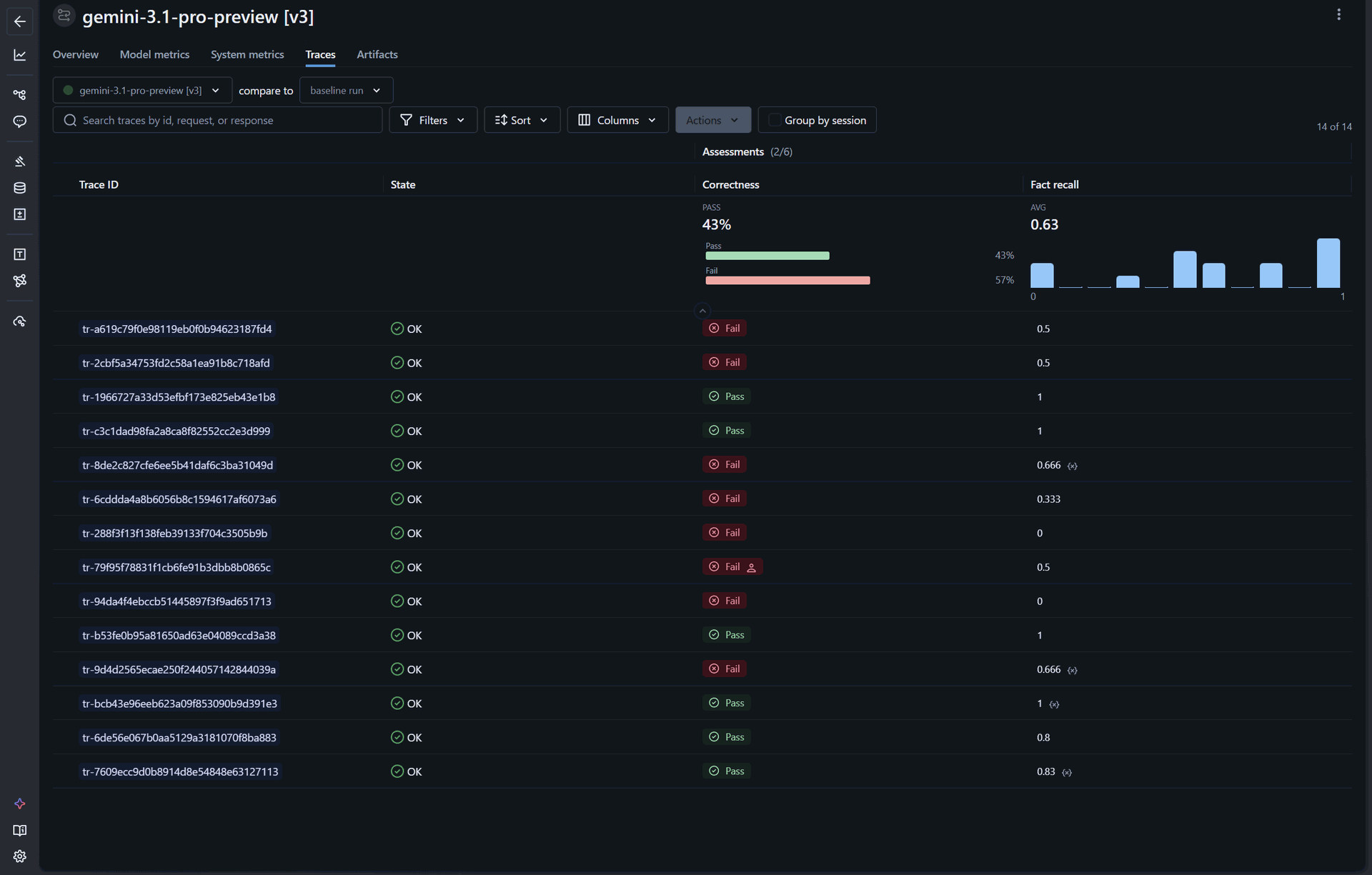
- Correctness: 43% (+7 punti)
- Fact recall medio: 0.63 (+0.25)
Qui il dato davvero significativo è il salto del fact recall: +0.25 in una sola iterazione. Il preprocessing dà al modello un input di partenza molto più "leggibile", e questo si traduce in risposte molto più dense di fatti corretti. La correctness cresce in modo più contenuto perché alcuni casi al limite continuano a essere classificati come Fail anche con più fatti corretti dentro.
Iterazione v4 — Refinement finale. A questo punto abbiamo affinato ulteriormente prompt, filtri sul vector store per componente, regole di selezione dei tool. Alcune conversazioni del dataset originale sono state riviste perché la stessa domanda si è rivelata, a posteriori, ambigua anche per gli ingegneri del cliente — segno che l'evaluation non serve solo a valutare il modello, ma anche a scoprire ambiguità nel dominio che altrimenti sarebbero rimaste nascoste.
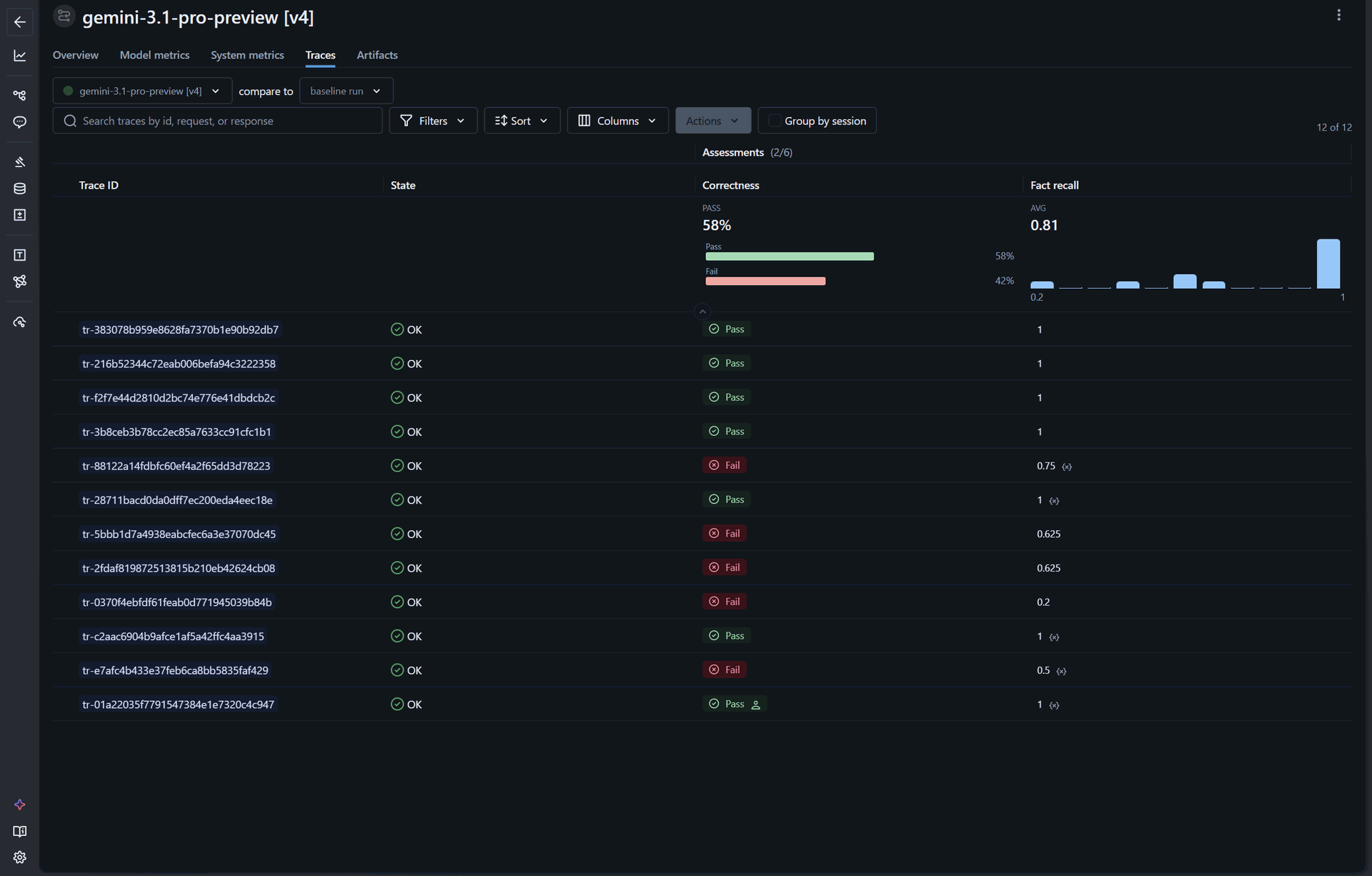
- Correctness: 58% (+15 punti)
- Fact recall medio: 0.81 (+0.18)
Rispetto alla baseline v1, su un dataset selezionato apposta per essere ostico, siamo passati da 14% a 58% di correctness e da 0.26 a 0.81 di fact recall. Queste metriche non sono il punto d'arrivo — il progetto è in pre-produzione e il lavoro continua — ma sono la prova che ogni modifica architetturale al sistema produce effetti misurabili, che possiamo isolare, che possiamo difendere davanti a un cliente.
Perché tutto questo conta. Torniamo al punto iniziale. Nel progetto del Cliente A avevamo una metrica binaria (match / no match) e abbiamo iterato fino a portarla al 100% in poche iterazioni. Nel progetto del Cliente B la metrica stessa è composita (correctness, fact recall, completeness, groundedness), il 100% non è un obiettivo realistico su un dataset difficile, e ogni cambiamento architetturale può migliorare un aspetto e peggiorarne un altro.
Senza un framework di eval come MLflow, decidere se un cambio di modello o di prompt "è un miglioramento" diventerebbe una questione di impressione. Con il framework diventa una questione di confronto numerico, misurabile, tracciabile e — questo è il punto cruciale per un IT Manager — auditabile. Se domani il sistema in produzione inizia a comportarsi peggio, abbiamo la traccia storica di cosa è cambiato e di come ogni modifica ha impattato le metriche. È l'equivalente dei test di regressione, ma per un sistema probabilistico.
Conclusione
I due progetti raccontano due livelli diversi di complessità AI, ma condividono un messaggio comune: nel mondo dei sistemi basati su LLM, la differenza tra un prototipo che funziona sulle demo e un sistema che funziona in produzione sta nella qualità del sistema di eval.
Il software tradizionale ci ha insegnato che non si può dimostrare la correttezza di un programma in senso assoluto — il teorema di Rice ce lo ricorda — ma si può costruire una rete di test sufficientemente fitta da catturare i regressi e guidare lo sviluppo. Il TDD ha formalizzato questo principio in una pratica operativa.
Nei sistemi AI la sfida è analoga ma su un piano diverso: l'output non è più vero o falso, ma più o meno buono secondo criteri multipli. Servono quindi strumenti nuovi — dataset etichettati, scorer LLM-as-a-judge, framework come MLflow — e soprattutto un cambio di mentalità da parte del team. Non si "testa" un sistema AI nel senso tradizionale; si valuta, si confronta, si itera.
Per un IT Manager che sta valutando un investimento in un progetto AI, le domande giuste da porre al fornitore non sono "quale modello usate?" o "che accuratezza raggiungete?". Sono:
- Come misurate le metriche di qualità e come le tracciate nel tempo?
- Se cambiamo il modello sottostante tra sei mesi — cosa che succederà — avete un modo di dimostrare se il sistema sta andando meglio o peggio?
- Avete un piano per il monitoraggio in produzione, non solo per lo sviluppo?
L'impostazione di un progetto AI solido si riconosce dalle risposte a queste domande, non dalla demo iniziale. E questo, al netto di tutta la complessità tecnica sottostante, è forse la differenza più importante da cogliere rispetto allo sviluppo software classico.
Se il tema vi interessa, in QTNova stiamo costruendo esperienza sistematica sulla messa in produzione di sistemi basati su LLM. Per una conversazione non impegnativa sul vostro caso specifico, scriveteci.
Vuoi saperne di più? Lasciaci una mail qui sotto, ti ricontattiamo al più presto.